> ## Documentation Index
> Fetch the complete documentation index at: https://docs.moderationapi.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Thresholds
> Tune what counts as flagged for each policy and what action the channel takes by default. These are your two main dials for the false positive / false negative trade-off.
A channel has two layers of thresholds:
1. **Per-policy thresholds** decide *what counts as flagged* for each policy.
2. **Severity score triage** decides *what action to take* when content is flagged and no [content rule](/content-moderation/rules) matches.
Both live on the channel and can be tuned independently. Most teams start with the defaults, watch a few hundred items go through, then nudge the dials based on what they see in the review queue.
***
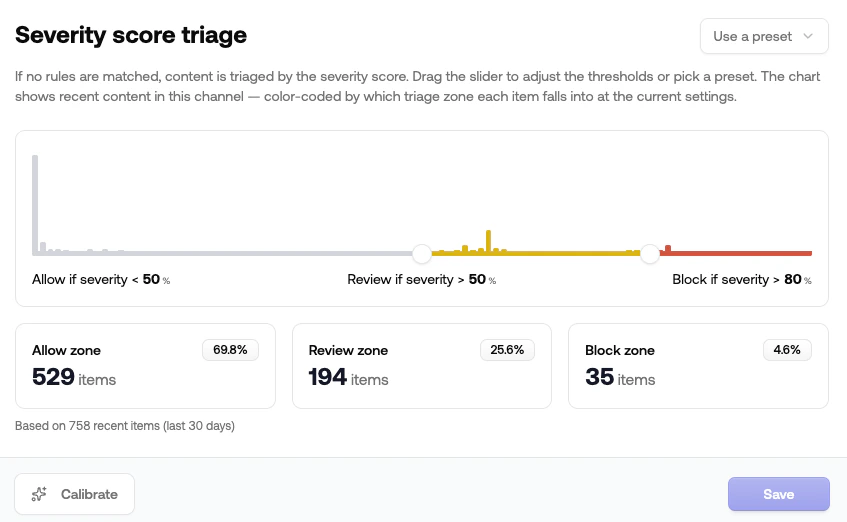
## Severity score triage
When a moderation request doesn't match any content rule, the channel falls back to **severity score triage**. Triage takes the request's `severity_score` (a 0–1 number summarizing how problematic the content is) and assigns Allow, Review, or Reject based on two thresholds.
### Where to find it
Open your project, pick a channel, go to **Rules**, and scroll to **Severity score triage**.
### The two thresholds
| Threshold | Default | What it does |
| ---------------- | ------- | ------------------------------- |
| Review threshold | `50%` | Below this, content is allowed |
| Block threshold | `90%` | Above this, content is rejected |
Anything between the two is sent to **review**.
The card shows a histogram of recent severity scores in this channel, color-coded by which zone each item falls into at the current settings. You can see how a slider change would shift your review queue load and reject rate before you save.
 ### Presets
Use the preset dropdown for a starting point:
| Preset | Review / Block | When to use |
| ----------------- | -------------- | ------------------------------------------------------------ |
| Strict | `40% / 70%` | Conservative platforms that want to minimize false negatives |
| Balanced | `50% / 90%` | Default for most general-purpose moderation |
| Forgiving | `70% / 95%` | Communities tolerant of edge cases |
| Skip reviewing | `75% / 75%` | Auto allow or reject, no review queue |
| Always review | `50% / 100%` | Send borderline content to review, never auto-reject |
| Review everything | `0% / 100%` | Manual moderation, every flagged item goes to a human |
| Allow everything | `100% / 100%` | Observe-only mode, log scores but never block |
### Disable triage
Toggle the switch on the **Severity score triage** row in the rules list to turn the fallback off completely. With triage disabled, anything that doesn't match a rule is allowed.
This is useful when:
* You've moved all your decision logic into [content rules](/content-moderation/rules) and want a single source of truth.
* You're observing the system in shadow mode and want every request to pass through unless a rule says otherwise.
### Calibration helper
The **Calibrate** button on the severity triage card pulls items your team has already resolved in the [review queue](/review-queues/overview) and recommends thresholds that maximize agreement between your pipeline and your moderators' decisions.
The flow is:
1. Pull a sample of resolved items (allowed and rejected) from the queue.
2. Compare the severity scores of allowed vs. rejected items to find the natural review zone.
3. Preview the suggested thresholds against your data before applying.
You'll get the most useful recommendations after your team has resolved a few hundred items in the queue.
***
## Per-policy thresholds
Each classifier policy returns a `probability` between `0` and `1` for every request. The **detection threshold** is the cutoff at which that probability flips the policy's `flagged` flag from `false` to `true`.
A flagged policy contributes to the overall severity score, can be referenced directly in [content rules](/content-moderation/rules#available-signals) (e.g. *Toxicity is Flagged*), and surfaces in the review queue.
### Where to find it
Open a channel, go to **Policies**, pick the category (Toxicity, NSFW, Illicit, ...), expand the policy, and select the **Threshold** tab.
### Presets
Use the preset dropdown for a starting point:
| Preset | Review / Block | When to use |
| ----------------- | -------------- | ------------------------------------------------------------ |
| Strict | `40% / 70%` | Conservative platforms that want to minimize false negatives |
| Balanced | `50% / 90%` | Default for most general-purpose moderation |
| Forgiving | `70% / 95%` | Communities tolerant of edge cases |
| Skip reviewing | `75% / 75%` | Auto allow or reject, no review queue |
| Always review | `50% / 100%` | Send borderline content to review, never auto-reject |
| Review everything | `0% / 100%` | Manual moderation, every flagged item goes to a human |
| Allow everything | `100% / 100%` | Observe-only mode, log scores but never block |
### Disable triage
Toggle the switch on the **Severity score triage** row in the rules list to turn the fallback off completely. With triage disabled, anything that doesn't match a rule is allowed.
This is useful when:
* You've moved all your decision logic into [content rules](/content-moderation/rules) and want a single source of truth.
* You're observing the system in shadow mode and want every request to pass through unless a rule says otherwise.
### Calibration helper
The **Calibrate** button on the severity triage card pulls items your team has already resolved in the [review queue](/review-queues/overview) and recommends thresholds that maximize agreement between your pipeline and your moderators' decisions.
The flow is:
1. Pull a sample of resolved items (allowed and rejected) from the queue.
2. Compare the severity scores of allowed vs. rejected items to find the natural review zone.
3. Preview the suggested thresholds against your data before applying.
You'll get the most useful recommendations after your team has resolved a few hundred items in the queue.
***
## Per-policy thresholds
Each classifier policy returns a `probability` between `0` and `1` for every request. The **detection threshold** is the cutoff at which that probability flips the policy's `flagged` flag from `false` to `true`.
A flagged policy contributes to the overall severity score, can be referenced directly in [content rules](/content-moderation/rules#available-signals) (e.g. *Toxicity is Flagged*), and surfaces in the review queue.
### Where to find it
Open a channel, go to **Policies**, pick the category (Toxicity, NSFW, Illicit, ...), expand the policy, and select the **Threshold** tab.
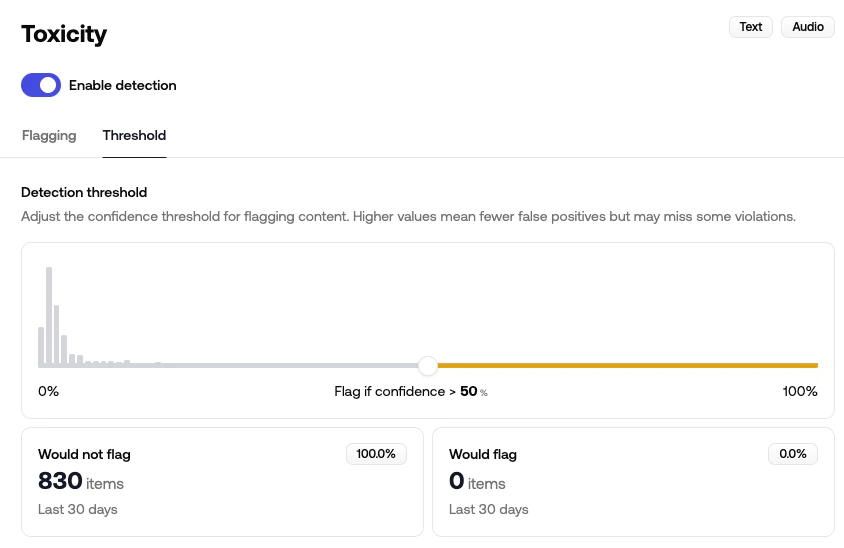 ### How to tune it
The slider shows a histogram of recent confidence scores for that policy. As you move the slider:
* **Bars to the left** of the slider are below threshold → not flagged
* **Bars to the right** are at or above threshold → flagged
Two KPI cards show how many recent items would have flipped sides. Use this to size the impact before saving.
A general rule:
* **Lower the threshold** if you're seeing false negatives: content you'd want flagged is slipping through.
* **Raise the threshold** if you're seeing false positives: borderline content is being flagged unnecessarily.
Click **Reset** to revert to the system default for that policy.
### Flag vs. shadow flag
Each policy also has a **Flagging** tab with two options:
| Option | Behavior |
| -------------------------- | ------------------------------------------------------------------------------------------------------------------------------ |
| Flag content when detected | Standard. Crossing the threshold sets `flagged: true`, contributes to severity, and the policy can be referenced in rules |
| Shadow flag when detected | The policy still scores content but doesn't mark it flagged. Items still appear in the queue under the *shadow flagged* filter |
### How to tune it
The slider shows a histogram of recent confidence scores for that policy. As you move the slider:
* **Bars to the left** of the slider are below threshold → not flagged
* **Bars to the right** are at or above threshold → flagged
Two KPI cards show how many recent items would have flipped sides. Use this to size the impact before saving.
A general rule:
* **Lower the threshold** if you're seeing false negatives: content you'd want flagged is slipping through.
* **Raise the threshold** if you're seeing false positives: borderline content is being flagged unnecessarily.
Click **Reset** to revert to the system default for that policy.
### Flag vs. shadow flag
Each policy also has a **Flagging** tab with two options:
| Option | Behavior |
| -------------------------- | ------------------------------------------------------------------------------------------------------------------------------ |
| Flag content when detected | Standard. Crossing the threshold sets `flagged: true`, contributes to severity, and the policy can be referenced in rules |
| Shadow flag when detected | The policy still scores content but doesn't mark it flagged. Items still appear in the queue under the *shadow flagged* filter |
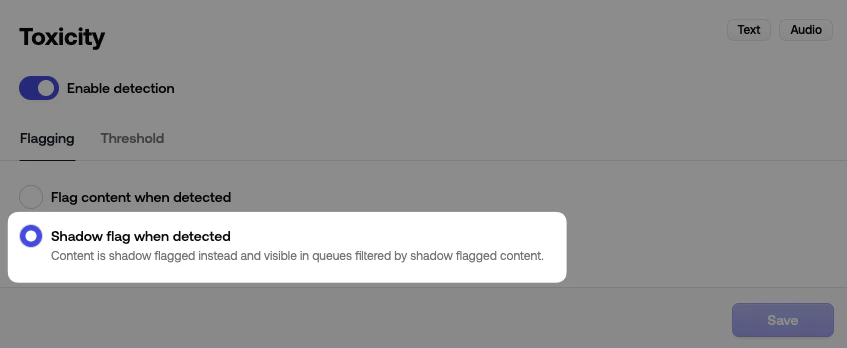 Shadow flagging is useful for testing a new policy in production without changing what your users experience. You can watch how it would score real traffic, validate it against your moderators' decisions, then switch it on for real.
***
## How the two layers interact
For a single moderation request, here's the order things happen in:
Every enabled policy returns a `probability`. Per-policy thresholds decide which policies set `flagged: true`.
Flagged policies contribute to the overall `severity_score`. Higher-weight categories (e.g. severe toxicity) push the score up faster.
Your [rules](/content-moderation/rules) run top-to-bottom. The first match decides the recommended action.
If no rule matches, the severity score triage thresholds decide the action: Allow, Review, or Reject.
So per-policy thresholds control *what gets flagged* and shape the severity score. Severity triage thresholds control *what action is taken* when no rule explicitly handles the case.
If you want a category to never auto-reject regardless of score, write a [rule](/content-moderation/rules) that catches it. Rules run before triage, so a matching rule wins.
***
## Tips
* **Change one dial at a time.** If you raise a policy threshold *and* lower the review cutoff in the same save, you won't know which one moved the queue.
* **Watch the histogram, not just the numbers.** A 5-point slider move can shift hundreds of items between zones if your traffic clusters around that score.
* **Hold off on Calibrate until you have a meaningful sample.** A handful of resolved items isn't enough to tune from, so let the queue accumulate first.
* **Pair shadow flagging with [Simulate](/content-moderation/rules#simulate-before-saving).** Shadow flagging previews how a policy would score real traffic; Simulate previews how the rules would route it. Neither touches what your users see.
Shadow flagging is useful for testing a new policy in production without changing what your users experience. You can watch how it would score real traffic, validate it against your moderators' decisions, then switch it on for real.
***
## How the two layers interact
For a single moderation request, here's the order things happen in:
Every enabled policy returns a `probability`. Per-policy thresholds decide which policies set `flagged: true`.
Flagged policies contribute to the overall `severity_score`. Higher-weight categories (e.g. severe toxicity) push the score up faster.
Your [rules](/content-moderation/rules) run top-to-bottom. The first match decides the recommended action.
If no rule matches, the severity score triage thresholds decide the action: Allow, Review, or Reject.
So per-policy thresholds control *what gets flagged* and shape the severity score. Severity triage thresholds control *what action is taken* when no rule explicitly handles the case.
If you want a category to never auto-reject regardless of score, write a [rule](/content-moderation/rules) that catches it. Rules run before triage, so a matching rule wins.
***
## Tips
* **Change one dial at a time.** If you raise a policy threshold *and* lower the review cutoff in the same save, you won't know which one moved the queue.
* **Watch the histogram, not just the numbers.** A 5-point slider move can shift hundreds of items between zones if your traffic clusters around that score.
* **Hold off on Calibrate until you have a meaningful sample.** A handful of resolved items isn't enough to tune from, so let the queue accumulate first.
* **Pair shadow flagging with [Simulate](/content-moderation/rules#simulate-before-saving).** Shadow flagging previews how a policy would score real traffic; Simulate previews how the rules would route it. Neither touches what your users see.